| Contrary to popular myth, the computer industry doesn't
always move at lightning speed. Truly fundamental
technologies such as the Internet, graphical user
interfaces, object-oriented programming, and RISC can take
years or even decades to evolve before winning broad
commercial success. And the inevitable early failures can
fool pundits into dismissing new trends prematurely. The trick is figuring out which blips on the radar screen are significant and which are meaningless ground clutter. In the case of IA-64 — the new 64-bit CPU architecture devised by Intel and Hewlett-Packard — the blip is significant indeed. One obvious reason is that IA-64 is the heir apparent to Intel's dominant but aging x86 architecture. What's less obvious is that IA-64 is the latest attempt to commercialize some "new" parallel processing and compiler technologies that dozens of companies and universities have been developing for at least 20 years. To report this story, BYTE talked to CPU architects and engineers at competing companies as well as at Intel and HP. We also interviewed academic researchers and computer scientists who have spent years working on the basic technologies behind IA-64. Conclusion: When Intel and HP say their new architecture goes "beyond RISC," it's not just marketing hype. IA-64's roots are decades deep, and it represents the general forward trend in microprocessor design. EPIC vs. RISC The basic techniques behind IA-64 are instruction-level parallelism, long or very long instruction words (LIW/VLIW), and branch predication (not the same thing as branch prediction). Intel and HP refer to this combination as explicitly parallel instruction computing, or EPIC. (See "Beyond Pentium II," December 1997 BYTE.) EPIC is a broad definition, like CISC or RISC. Anybody can design a CPU architecture based on EPIC. IA-64 is the first example: It's a proprietary CPU architecture defined by Intel and HP, just as Intel's x86 is a proprietary architecture based on CISC and HP's PA-RISC is a proprietary architecture based on RISC. Merced is the code name for the first IA-64 processor that Intel plans to ship in the second half of 1999. More IA-64 chips will follow, all from Intel. (HP is a partner but will not independently design, manufacture, or sell any IA-64 chips.) "Just as RISC represented a revolution in processor technology over CISC, EPIC represents a revolution in processor technology over RISC," says Carol Thompson, a compiler architect at HP. It's not an empty claim. EPIC is the result of work that started long before Intel and HP formed their IA-64 partnership in 1994. Two direct ancestors are the highly parallel VLIW machines designed by Multiflow and Cydrome in the 1980s. Although both companies are defunct, a remarkable number of their former employees now work at Intel, HP, and satellite companies. More distant ancestors of EPIC are parallel-processing systems designed by IBM, Control Data, Digital, Loral, MasPar, Cray Research, Thinking Machines, and others. Additional research at universities has been under way for decades. This background is important for two reasons. First, it shows that EPIC is part of a slowly cresting wave, not merely a ripple. Just as RISC can trace its roots back to the pioneering work of John Cocke at IBM in the 1960s and 1970s, EPIC can trace its heritage back to the 1970s and 1980s. CPU architectures have been moving in this general direction for a long time. EPIC was more or less inevitable, with or without Intel and HP. Second, the long gestation period means EPIC is not built on experimental, unproven technology. This is especially important for the compiler technology — EPIC relies more heavily on optimized compilers than RISC or CISC does. It will probably take a few years' experience in the field to refine the compilers and processors, but the first examples should give users a glimpse of IA-64's potential. Limits of RISC EPIC tries to address the shortcomings of RISC, just as RISC addressed the shortcomings of CISC. Those shortcomings — as perceived by EPIC proponents — are the limits of hidden parallelism and the increasing complexity of dynamic instruction scheduling. Basically, there are two ways to make a faster CPU. One way is to increase the clock frequency, which increases the number of operations a CPU performs each second. All other things being equal, a 200-MHz processor is twice as fast as a 100-MHz processor. Fortunately, higher clock speeds are a natural byproduct of shrinking circuits. The other way to make a faster CPU is to increase the number of operations it can perform per clock cycle. Modern RISC and CISC processors do this with two techniques: instruction pipelining and superscalar microarchitectures. Pipelining works like a factory assembly line. It divides the execution path into stages, so the CPU can work on multiple instructions at a time, with each instruction at a different state of completion. Superscalar processors have two or more of those pipelines, so they can work in parallel on multiple instructions. If achieving higher performance were as easy as adding more and deeper pipelines, engineers could go home at 5 o'clock. Unfortunately, they soon hit a wall of diminishing returns. The main problem is finding enough work to keep all those pipelines busy. Program code is rarely suitable for parallel processing because it's riddled with control-flow instructions that change the path of execution. Those pesky instructions include branches (IF-THEN-ELSE), loops (FOR-NEXT, WHILE-DO), jumps to subroutines (calls to functions, procedures, and methods), and error handlers (TRY-CATCH, ON ERROR). Of course, those are the same instructions that make software useful. Some scientific programs have long sequences of calculations that are easy to execute in parallel, but most code has a branch every five or six instructions. Because the CPU doesn't know for sure which way a branch will fork — it often depends on user input — the CPU must resolve the branch before executing any instructions beyond it. So there's little point in having 10 pipelines if the CPU can't execute more than five or six instructions in parallel before hitting a branch barrier. To get around that problem, modern RISC and CISC processors resort to a variety of techniques: branch prediction, speculative execution, and out-of-order execution. The first two allow a CPU to make a good guess about which way a branch will jump so the CPU can begin executing instructions along the predicted path. That way, the CPU can fill more instruction slots in its pipelines before resolving the branches. The third technique, out-of-order execution, tries to keep the pipelines busy by rearranging a program's instructions at run time. If an integer instruction is immediately followed by a floating-point instruction, but all the integer units are busy, the CPU might begin executing the FP instruction first and come back to the integer instruction later. A conventional in-order CPU would stall until an integer unit becomes available. But these three solutions create new problems. If the CPU mispredicts a branch, it must flush its pipelines of the partially completed instructions to make way for the correct instructions. The more pipelines, and the deeper the pipelines, the bigger the penalty in lost clock cycles. A processor with four seven-stage pipelines might lose 28 cycles (4 x 7), not counting the additional cycles it may require to reload the cache. A processor that's twice as wide and twice as deep could lose 112 cycles (8 x 14). The penalty becomes so enormous that it wipes out the gains of parallelism. Out-of-order execution has a price, too. The CPU needs complex interlock circuitry and a large register file to juggle the instructions. It has to work fast, because it's rescheduling the instructions while the program is running. It can't see more than a small piece of the program at any one instant. And out-of-order CPUs are much more difficult to verify. Digital's 21264, the first fully out-of-order Alpha processor, was delayed for months while engineers labored to verify its complex design. The first out-of-order CPUs from Intel (Pentium Pro) and Mips (R10000) were difficult to verify as well. Some companies, such as Sun, are avoiding out-of-order execution altogether. CPU architects are eager to solve those problems because new fabrication technology will soon make it possible to build chips with hundreds of millions of transistors. If there's nothing to gain by adding more functional units, they'll have to dump those transistors into bigger on-chip caches. Although bigger caches improve performance to a degree, architects would rather spend their growing transistor budgets on parallel logic that does more useful work. The EPIC Solution EPIC tries to address the limitations of today's architectures by encoding parallelism at the instruction level and by using branch predication. Instruction-level parallelism (ILP) requires a compiler to statically schedule the instructions at compile time, instead of waiting for the CPU to schedule them dynamically at run time. Compilers already do this to some extent. But a regular compiler has no way to explicitly tell a CPU which instructions it can issue in parallel. At run time, the CPU must scan the instruction stream to find the parallelism. An out-of-order CPU goes even further by reordering the instructions again, seeking "hidden" parallelism the compiler missed. An EPIC compiler schedules the instructions at compile time and exposes the code's parallelism to the CPU. IA-64 defines a template field that encodes this information within a few bits. The CPU reads the template at run time and knows immediately which instructions it can dispatch in parallel to the functional units. Because an EPIC processor doesn't have to schedule dynamically, it doesn't need as much complex interlock circuitry as an out-of-order RISC or CISC processor. Theoretically, it can be smaller and cheaper. Another advantage of static scheduling is that a compiler can spend a relatively luxurious amount of time doing global optimizations. At run time, a CPU has only a few nanoseconds to do its job and sees only a tiny fragment of a large program at any moment. A compiler has much more time to analyze the code and sees the whole program (except for any dynamically loaded pieces, such as DLLs or late-loaded class files). The counterargument is that CPUs know more about a program's actual behavior at run time. "It's a question of how much you can do in hardware versus how much you can do in software," says Mike Splain, chief technology officer at Sun Microelectronics. Although recent RISC and CISC processors have been doing more dynamic scheduling in hardware, proponents of ILP are betting on the compilers. "At run time, the CPU knows almost everything, but it knows everything almost too late to do anything about it," says Gerrit A. Slavenburg, chief architect of the Philips TriMedia processor, a VLIW design. Parallel Encoding IA-64's templates are a relatively new innovation. Earlier attempts by Multiflow and Cydrome to build highly parallel systems were hampered by designs that bound the compilers too tightly to the microarchitectures. (The microarchitecture is the specific design of a chip, as distinct from the overall defining architecture.) For example, Multiflow's Trace 28/200 matched 256-bit instruction words to specific processor clusters. Each 256-bit word contained seven operations, and each processor cluster could execute seven operations per cycle. If the type of operations didn't exactly match the type of functional units available, the compiler had to pad the instruction word with NOPs — null operations. To reduce code size and conserve I/O bandwidth, Multiflow compressed NOPs in memory, then expanded them in the instruction cache after fetching. But Multiflow's approach still wasted instruction slots and forced developers to recompile programs if the system's microarchitecture changed. IA-64 takes a different approach. IA-64 has long instruction words, too, although they're only 128 bits long. Each word contains three instructions and a template. The template not only tells the CPU which instructions in the word can issue in parallel with each other, but also which instructions in the following words can issue in parallel. This requires some interlock circuitry, but it's much simpler than the interlocks in an out-of-order RISC chip. And there's no binding relationship between word width and CPU width. Let's say an IA-64 compiler finds eight integer instructions that have no mutual dependencies, so they can issue in parallel. It packages those instructions into three words — two complete words and part of a third. The compiler doesn't have to pad the remaining slot in the third word with a NOP; instead, it fills the slot with a useful instruction that can't issue in parallel with the others. Now assume the compiled program runs on an IA-64 processor that has four integer units. The CPU reads the templates and instantly knows the next eight instructions can execute in parallel. But the CPU has only four integer units, so it needs two cycles to execute all eight instructions (assuming single-cycle operations). If the same program runs on a different IA-64 processor that has eight integer units, the CPU could execute all eight instructions in one cycle. That's how IA-64 ensures code compatibility between generations — a significant improvement over the Multiflow and Cydrome architectures. (See the figure "IA-64 Code Compatibility".) IA-64's templates don't solve every problem, however. "There are two issues with changing the microarchitecture: compatibility and performance," says Richard Lethin, a former Multiflow engineer who is now president of Equator Technologies Consulting, which specializes in VLIW compilers, dynamic compilers, and emulators. "You can change the microarchitecture without breaking compatibility, but if you want maximum performance, you still have to recompile. Definitely." Also, note that some functional units remain idle if they can't handle the type of instructions chained together. (FPUs cannot execute integer operations, or vice versa.) But it's still better than padding with NOPs. Branch Predication A good EPIC compiler must know enough about a processor's microarchitecture to balance the trade-offs between branch prediction and branch predication. One goal of predication is to dodge the penalty of mispredicted branches — a penalty that gets much worse as CPUs get wider and deeper. Merely increasing the accuracy of branch prediction isn't enough. Even static branch prediction is about 87 percent accurate, notes Stan Head, technical marketing manager at Mips. Intel's Pentium Pro and Pentium II use dynamic prediction to achieve better than 90 percent accuracy, and for good reason: With three 15-stage pipelines, it costs them as many as 45 clocks to flush their pipes after a bad guess. Future processors with dozens of pipelines would pay outrageous penalties. Predication effectively eliminates some branches from compiled code by using conditional execution. In IA-64, if the compiler decides to predicate a branch, it assigns all instructions along one path to a unique predicate register, and all instructions along the alternate path to a complementary predicate register. At run time, the CPU begins executing instructions from both paths in parallel. When the CPU resolves the branch condition, it writes TRUE in one of the predicate registers and FALSE in the other. Instructions finish executing only if they find TRUE in their matching predicate register. Since there's no longer a branch, there's nothing to predict, so there's no chance of guessing wrong. Yes, the CPU wastes some cycles executing instructions that never complete. But it's cheaper than the huge penalty of misprediction. And eliminating branches makes it easier for the CPU to schedule the larger, unbroken blocks of code in parallel. Predication doesn't stop an EPIC compiler from predicting some branches. Jumps to error-handling routines are rare, so a smart compiler would predict the program won't take that branch. Likewise, a FOR loop with 1000 iterations will predictably jump backward to the top of the loop 1000 times, so it's a safer bet than predication. The compiler needs to know enough about the CPU's misprediction penalty to make those decisions. That's why developers will have to recompile their IA-64 software for each generation if they want the best performance — but today's architectures demand that, too. Predication, to various degrees, is found in architectures as diverse as the Advanced RISC Machines ARM, the Philips TriMedia, the Mips Rx000, the Sun SPARC, the Digital Alpha, the Texas Instruments TMS320C6xx DSP, and even the ancient x86. In its simplest form, predication appears in an instruction called a conditional move (CMOV). It's easier to attach conditional execution to a single type of instruction than to a whole instruction set. It's also possible to retrofit an old instruction set with CMOVs. Intel added CMOVs to the P6 generation (Pentium Pro and Pentium II) in 1995. They've been in the Rx000 since 1995, the Alpha since 1992, and SPARC since 1991. CMOVs execute only if a condition code is TRUE. Usually there isn't a special predicate register. Predicating only one type of instruction on a single condition may seem insignificant, but it makes a difference. According to Stan Head at Mips, about 60 percent of all IF-THEN-ELSE blocks consist entirely of move instructions, so CMOVs can eliminate enough branches to be worthwhile. Although CMOVs are useful, Digital decided against making every instruction conditional, as in IA-64. The additional gain wouldn't pay off, claims Aaron Bauch, technical marketing manager for the Alpha. Naturally, Intel disagrees: "A more generalized predication model allows the processor to execute longer streams of instructions in parallel," says Carole DuLong, IA-64 principal engineer. ARM has more experience with predication than practically anyone. All ARM instructions can predicate on 16 possible conditions — a remarkably advanced feature of the architecture since its inception in 1983, says Dave Jaggar, director of ARM's Austin Design Center in Texas. However, ARM processors can predicate through only one branch. That's still a big win because branches occur only about once every eight or nine instructions in ARM code, notes Jaggar. But IA-64 provides 64 predicate registers, so theoretically it could predicate through 32 nested branches. TI's DSP and Philips' TriMedia are more modern and specialized architectures. Both have fully predicated instruction sets, like IA-64. But TI uses general-purpose registers (GPRs) for predicate registers and devotes only five to that purpose. That's enough for the highly parallel code typically encountered by DSPs, says Henry Wiechman, DSP product marketing manager. "DSP algorithms are more deterministic than general PC applications like Microsoft Word." Likewise, the TriMedia TM1000 uses GPRs instead of special predicate registers. Multimedia processors frequently execute highly parallel code in audio/video streams, so they don't need to predicate as many branches as regular CPUs. The point is that predication is not a black art. Allowing a CPU to start executing both forks of a branch before the user chooses "OK" or "Cancel" might seem a little spooky, but it's just another long-used technique that blooms anew in IA-64. The EPIC Gamble Intel and HP aren't alone in their enthusiasm for EPIC and VLIW. "VLIW is the next revolution in microprocessors," declares Nat Seshan, applications manager for TI's DSPs. "It will definitely bring more high performance to users." Gerrit Slavenburg, the TriMedia architect, agrees: "Philips has invested a lot in VLIW because we determined it was the best way to get high performance at a low cost. It is the best architecture I know of at this point." However, that doesn't necessarily mean that Merced will be the world's fastest microprocessor out of the gate. RISC still has plenty of headroom, and EPIC will take time to gain speed. "I have a suspicion that a good out-of-order machine can do better with most applications than Merced," says Stan Head at Mips. The current speed champ is the Alpha 21264, the first Alpha that executes out of order. It's twice as fast as the in-order Alpha 21164 at the same clock frequency. Digital says the 21264 will run at 1 GHz (1000 MHz) in the year 2000, shortly after Merced arrives. According to Digital's Aaron Bauch, the 1-GHz chip will score better than 100 on the SPECint95 integer benchmark and higher than 150 on the SPECfp95 FP benchmark. That's about twice the rumored integer performance of Merced and about three times its rumored FP performance. Moreover, Digital expects the 21264's die to be about half the size of Merced's on the same 0.18-micron CMOS process — despite the extra interlock circuitry Alpha needs to manage out-of-order execution. How fast can Intel ramp up IA-64's performance? Intel plans to introduce a second IA-64 chip in 2001 that's about twice as fast as Merced. But it probably won't be until 2004, when a true second-generation IA-64 chip will likely appear, that we'll get a clearer picture of IA-64's genuine potential. By then, CPUs could have 200 million transistors -- enough, perhaps, to settle the debate about which architecture makes the best use of those resources. If RISC suffers diminishing returns from dynamic scheduling while EPIC's performance scales on a more linear trajectory, the handwriting will be on the wall. But don't forget the other key variable: compilers. "My biggest fear about IA-64 is that bad compilers may ruin its reputation," says David August, a researcher at the University of Illinois (Urbana-Champaign). His masters and doctoral theses explore ILP and compiler predication, and he belongs to the Illinois Microarchitecture Project utilizing Advanced Compiler Technology (IMPACT), a research team that has spent years working on next-generation compilers. "Retargeting an existing compiler is simply not going to work," warns August. "IA-64 compilers need a new infrastructure to do predication, speculation, and static scheduling/optimization correctly. The IMPACT group knows this as fact, and some companies, including Intel, are learning this from us or are using our technology. However, I know some companies don't know not to take the retarget approach. It has always worked in the past for them. This time it is going to be very, very different." The VLIW veterans at Philips and TI agree. They've labored as long as 10 years on their highly tuned compilers. "Compiler design in some ways is even more complicated than machine design," notes Slavenburg. It's a tough call. The technology behind EPIC wins accolades from experts, but it's not certain that Intel and HP can break it out of the labs and into the mainstream. History shows that stellar technology does not always mean commercial success. Sidebar:Where to Find
Advanced RISC Machines
Multiflow's VLIW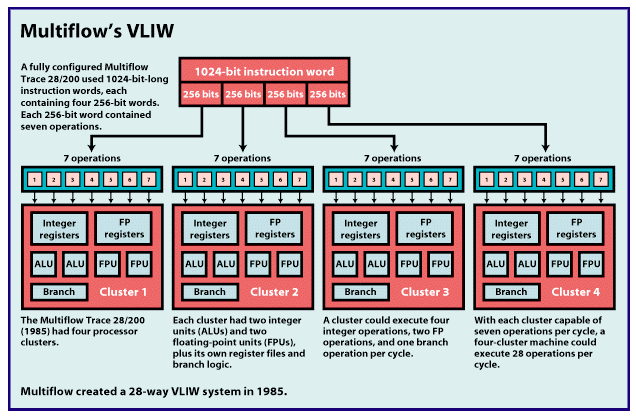 IA-64 Code Compatibility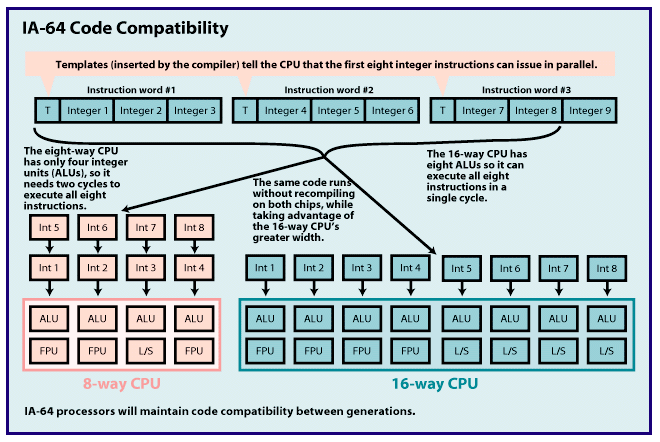 Trimming Branches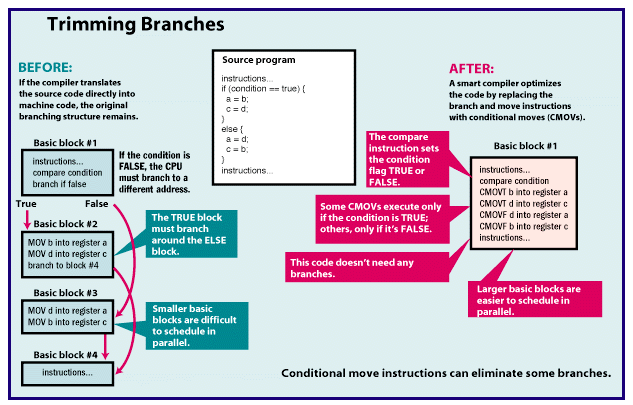 Tom R. Halfhill is a BYTE senior editor based in San Mateo, California. You can reach him at tom.halfhill@byte.com. Copyright © 1994-1998 BYTE |