| It takes a lot of nerve to add new instructions to the
x86 instruction set if your name isn't Intel. And it's
especially cheeky if you're a tiny company like NexGen,
barely a mosquito on Intel's back. Yet that's what NexGen hoped to do. Last October, the company announced its latest microprocessor, the Nx686. It was the first x86 chip to integrate a multimedia execution unit and a new set of multimedia instructions. Never before had anyone but Intel attempted such a bold revision of the 18-year-old x86 architecture. Could anyone take NexGen seriously? Then came stunning news. NexGen — which ranked last behind Intel, Advanced Micro Devices, and Cyrix as a vendor of x86-compatible chips — agreed to be acquired by AMD. And AMD promptly scrapped its own sixth-generation CPU project in favor of the Nx686, which will now be marketed as the AMD K6. The surprise announcement instantly boosted the prospects for NexGen's maverick microprocessor. AMD is a $2 billion company that has serious marketing muscle and high-profile customers, including five of the top six suppliers of PC compatibles. In addition, AMD has its own process technology and wafer-fabrication plants. NexGen, a fabless company, subcontracts its manufacturing to IBM Microelectronics. (This partnership may continue for some products, including the Nx586.) Suddenly, Intel faces stiffer competition for an emerging market of multimedia CPUs. While NexGen was developing the Nx686, Intel has been working on its own multimedia x86 processor, code-named the P55C. This Pentium variant will probably make its debut in the second half of this year, about the same time as the Nx686/K6. Intel isn't releasing many details, but we know the P55C will also define new multimedia instructions for the x86 architecture. Of course, Intel still wields more clout than AMD and NexGen. Only by joining forces with compiler vendors, software developers, and perhaps other chip makers can AMD ensure that the K6's multimedia extensions will survive alongside Intel's. Before the merger, NexGen claimed it was part of such an alliance but said the other members weren't ready to go public. When the time is ripe, company officials say, it will be apparent that the alliance has enough strength to make the extensions a de facto industry standard. That remains to be seen. Even without its multimedia enhancements, however, the K6 is still an impressive chip. If it lives up to expectations, the K6 could match or beat the performance of Intel's flagship processor, the Pentium Pro (formerly called the P6). Multimedia Marvels The K6's multimedia execution unit is one of seven execution units in the new processor. NexGen says it occupies only about 5 percent of the chip's die area. Because the K6 is not yet in production, NexGen won't reveal the actual die size, other than to claim it will be "substantially smaller" than the Pentium Pro's die of 306 square millimeters. The multimedia unit probably accounts for less than 300,000 of the K6's six million transistors. That's not a lavish expenditure in the transistor budget of a leading-edge microprocessor these days. But what does it buy? NexGen says the multimedia unit recognizes about 10 to 20 new instructions. All are designed to streamline multimedia processing, such as digitized audio, digitized video, 3-D graphics, MPEG-2 decompression, motion estimation, and pixel manipulation. According to Greg Favor, who directed the chip's development, the extended instructions are fairly general in nature, so they won't become obsolete as the industry defines new standards. One new instruction performs the same kind of multiply-accumulate (MAC) function often seen in digital signal processors (DSPs). Programmers can use the MAC instruction to multiply and add a series of numbers repeatedly without a branched program loop. It's faster than regular x86 code because the CPU doesn't have to execute separate instructions for the multiply and add operations or evaluate a branch during each iteration of the loop. NexGen won't say much about the other new instructions, except that they adhere to a single-instruction/multiple-data (SIMD) model, just like some DSPs. In other words, each instruction operates on multiple operands of data. That's ideal for multimedia, which typically consists of lengthy data streams that must be compressed, decompressed, or otherwise transformed. In concept, the K6's new instructions resemble a similar subset of multimedia instructions that Sun Microsystems defined for its UltraSparc processor in 1994. Externally, the new K6 instructions are as accessible to programmers as any other x86 instructions. However, NexGen hints that application programmers probably won't have to explicitly call the new instructions because they'll be encapsulated by higher-level APIs, such as Microsoft's Direct-X for Windows. Certainly an ally such as Microsoft would be useful to an industry alliance that wants to extend the x86 architecture without the blessing of Intel. (Microsoft has no comment on this.) Internally, the K6 translates the multimedia instructions into RISC86 operations — the RISC-like primitives that were the most innovative feature of the Nx586 when it appeared in 1994. The Nx586 was the first x86 processor to introduce this concept of a decoupled CISC/RISC microarchitecture. On the outside, to x86 software, the chip behaves like a normal x86 CPU. But inside, special decoders translate the variable-length CISC instructions into fixed-length (albeit long) RISC-like operations that execute in a RISC-like core. NexGen, Intel, and AMD are now using decoupled microarchitectures in all their latest CPUs. They believe it's a better approach than trying to execute multiple CISC instructions in parallel and out of order. The only holdout is Cyrix; engineers there say a decoupled microarchitecture will become too difficult to manage in wider superscalar designs. Favor says the K6's multimedia instructions are easy to execute in parallel because they're more efficient than most x86 instructions. Each one breaks down into just one or two RISC86 operations. The MAC instruction, for example, translates into a single RISC86 primitive that typically executes in a single cycle. According to NexGen, the multimedia unit can execute up to 6 billion operations per second (BOPS). That's amazing if true. The fastest general-purpose DSP — Texas Instruments' TMS 320C80 Multimedia Video Processor — executes about 2 BOPS. Until AMD makes the K6 available for independent benchmarking, however, it's unclear how often the processor will be able to sustain 6 BOPS. TI's chip appears to have more internal bandwidth, and it uses a multiple-instruction/multiple-data (MIMD) model instead of a SIMD model like the K6 uses. If the K6 comes anywhere close to sustaining 6 BOPS when running real-world multimedia software, it will be a significant accomplishment. Bottlenecks Begone There's a lot more to the K6 than its multimedia unit. The new chip fixes several shortcomings of the Nx586 by adding larger caches, multiple decoders, more registers, deeper queues, and additional execution units. As a result, the K6 is now a four-way superscalar processor; the Nx586 is a three-way design. However, NexGen has discarded two key features of the Nx586: the integrated cache controller and the dedicated bus for the secondary (level 2) cache. These were casualties of NexGen's last-minute decision to make the new chip pin-compatible with the P54C-series Pentiums. As a pin-compatible part, the K6 will work with the same peripheral chips as the Pentium — for example, PCI chip sets designed by third-party vendors. But the downside of this decision is that the K6, like the Pentium, now requires an external cache controller and will access its secondary cache (if present) over the same 64-bit bus it uses for memory I/O. Sharing the same bus hurts performance because of bus contentions. To compensate for this performance loss, NexGen has greatly expanded the K6's onboard cache. The primary (level 1) caches in the K6 now total 64 KB, compared to 32 KB in the Nx586 and only 16 KB in the Pentium. The caches are evenly split, with 32 KB each for instructions and data. Both caches are two-way set-associative and support the MESI protocols for cache-coherent multiprocessing. The data cache is dual-ported and isn't banked, thus eliminating bank conflicts. It can handle one read operation and one write operation per cycle. NexGen also added a 16-KB predecode cache that's closely coupled to the instruction cache (I-cache). The predecode cache holds special information that's generated when the K6 fills the I-cache. For example, as part of its predecoding, the K6 locates and marks the boundaries between x86 instructions, which are variable in length. (This step is unnecessary in a true RISC processor because RISC instructions are always fixed-length.) Predecoding speeds up full decoding further down the pipeline; AMD's K5 has a similar stage. However, one drawback of predecoding is that it lengthens the x86 instructions by appending extra information to them. In the case of the K6, each instruction byte gains 4 bits (1 nibble) of predecode data. This threatens to effectively reduce the working size of the I-cache by 50 percent. To avoid this size penalty, the K6 stores the extra nibbles in the 16-KB predecode cache. Then, when the K6 fetches instructions from the I-cache into the instruction buffer, it simultaneously retrieves the nibbles. The K6 also marks branch instructions during the predecode stage and calculates their target addresses. All branch predictions are based on a two-level dynamic algorithm with a 2-bit history flag (strongly taken, weakly taken, weakly not taken, and strongly not taken). The K6 stores these flags in an enormous branch-prediction table that can hold 8192 entries. It also stores the return addresses and target addresses in two additional caches that each hold 16 entries. As a result, the K6's branch prediction is well over 90 percent accurate, putting it in the same league as the Pentium Pro and ahead of other x86 processors. Parallel Decoding Where the Nx586 could decode only one x86 instruction per cycle because it had just one instruction decoder, the K6 has two decoders and can handle two x86 instructions per cycle. The Pentium Pro has three x86 decoders, but two of them can deal only with simple instructions, and the most complex instructions are detoured into a microcode ROM. NexGen claims the K6's decoders are more capable: They're not constrained by instruction groupings that would stall the Pentium Pro's simple decoders, and they can decode a larger subset of x86 instructions without using microcode. (Of course, the most complex or rarely used x86 instructions still invoke microcode.) NexGen says it considered adding a third decoder, but simulations revealed a performance gain of only 2 to 5 percent in return for a frequency loss of 15 to 20 percent — not a good trade-off. Although the maximum input to the decoders is two x86 instructions per cycle, the maximum output is four RISC86 operations each cycle. That's because the CISC instructions usually break down into two or more RISC-like primitives. Examples: INC register translates directly into a single RISC86 register operation; ADD register, memory gets reduced to a load operation and a register operation; ADD memory, register results in a load operation, a register operation, and a store operation. The worst x86 instructions can generate dozens or even hundreds of RISC primitives. In those cases, the K6 can issue as many as four RISC86 operations per cycle from its microcode ROM. The K6's pipeline gets wider toward the middle. During each clock cycle, two x86 instructions can enter the decoders; four RISC86 operations can exit the decoders; six operations can issue and execute; and four operations can retire. This bulge in the middle of the pipe minimizes bubbles and stalls and keeps the seven execution units from twiddling their thumbs. The traffic cop that manages all this action is the instruction control unit (ICU). It temporarily holds up to 24 RISC86 operations and issues them to the appropriate execution units. This is also where the instructions get out of order. The ICU can issue up to six instructions per cycle in any order to any available execution unit, as long as there are no dependencies between instructions. (An example of a true dependency is when one instruction depends on the result of a previous instruction.) To reduce the chances of so-called false dependencies — instances where register-dependent instructions might stall because there aren't any available registers — the K6 has a large set of 48 general-purpose registers, compared to 14 in the Nx586. Eight of them represent the eight logical registers of the x86 architecture. The K6 can temporarily rename the other 40 physical registers to represent any of the eight logical registers. When a register operation retires, the K6 copies its value into the corresponding architectural register. This is quite similar to how the Pentium Pro uses its set of 40 physical and eight logical registers. A feature called register-result bypassing allows the K6 to make completed results immediately available to subsequent instructions without accessing main memory. Because register operations are much faster than memory accesses, register-result bypassing can save numerous clock cycles. Also, NexGen claims the K6 is particularly fast at loading segment registers and at handling partial register operations. This means that it should outperform the Pentium Pro when running 16-bit software. However, the K6's ICU draws from a smaller pool of pending instructions than the Pentium Pro's instruction scheduler: 24 versus 40. And the ICU can't track more than 12 x86 instructions at a time. A larger instruction pool — which is a window into the running program — would allow more flexibility when issuing instructions out of order. Still, the K6 is more flexible in this regard than the Nx586. Execution Time In addition to its innovative multimedia unit, the K6 has six other execution units: a load unit, a store unit, two integer units, a branch unit, and an FPU. Again, this is a significant improvement over the Nx586, which has only three execution units and is the only fifth-generation x86 processor without an integrated FPU. The K6's separate load and store units will speed up memory reads and writes, a prominent barnacle on the hull of CISC instruction sets. Each unit has a two-stage pipeline. The store unit feeds results into a seven-entry queue that temporarily holds them until the CPU completes all previous instructions and resolves any dependencies. Holding them assures that all instructions retire in original program order, regardless of the order in which they executed. One exception: If a load operation depends on a pending store, the load can bypass the store and fetch the value directly from the results queue. Since this happens before the store unit actually writes the value to memory, it eliminates another slow memory access. The K6's two integer units are not symmetrical; one can handle a superset of arithmetic operations, including multiplication and division. Most operations execute in a single cycle, and multiplication requires only two cycles. Floating-point math appears to be fast, too. Although the K6's FPU is not as heavily pipelined as those in the Pentium and Pentium Pro, its latencies are shorter. NexGen says most floating-point additions, subtractions, and multiplications will execute in only two cycles. As mentioned, the branch unit is among the most efficient in any x86 processor. Much of its work is done early, because it calculates target addresses while decoding. If the correct target address isn't cached, the branch unit calculates and fetches the new target during the next stage, paying only a one-cycle penalty. However, if the branch unit mispredicts a branch, it needs about five cycles to recover — not an unreasonable penalty for a CPU whose predictions are more than 90 percent accurate. Overall, the K6's pipeline is five or six stages long, depending on the operation. Register and integer operations typically require five stages, and load/store operations need six. The K6 isn't superpipelined like the Pentium Pro, so it probably can't be driven to the same high clock frequencies. NexGen hopes to achieve superior performance with architectural efficiency, not extreme clock speeds. NexGen has been testing silicon samples of the chip since September, so the engineers can roughly estimate its actual performance. They say they expect that the K6, at equivalent clock speeds, will beat the Pentium Pro when running 32-bit software, and perhaps outrun it by as much as 33 percent. With 16-bit software, NexGen expects the K6 to run about twice as fast as a Pentium Pro. If the K6 can deliver that level of performance on a die as small as NexGen suggests, the new processor could achieve a significant price/performance advantage over Intel's top-of-the-line chip. When you throw in the multimedia goodies, the K6 looks even better. Of course, nobody — including AMD and NexGen — expects to dislodge Intel as the king of the x86 market. But the K6 chip could carve out a respectable niche and presage the multimedia microprocessors of the future. K6: What's New— Multimedia execution unit; first x86 CPU to have
one— New subset of multimedia instructions— Four-way superscalar pipelines— Hybrid CISC/RISC microarchitecture— Seven execution units, including FPU— Executes up to six operations per cycle— Out-of-order execution, dynamic branch
prediction, and speculative execution— Six million transistors— 32-KB primary instruction cache; 32-KB
primary data cache— Clock frequency at debut: 180 MHz— 0.35-micron, five-layer-metal, CMOS
process technology— Pin-compatible with P54C-series Pentiums— Claimed performance: At least as fast as
Pentium Pro with 32-bitsoftware; twice as fast with 16-bit software— Production scheduled for mid- to late 1996K6 Block Diagram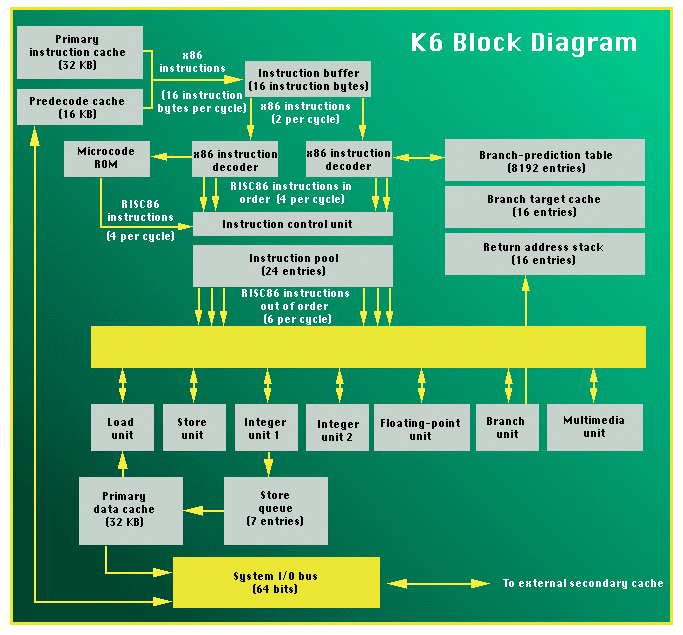 The K6 is a four-way superscalar processor with seven execution units; during each clock cycle, it can execute up to six instructions and retire four. At the far right of this diagram is the multimedia unit, which recognizes a new set of multimedia instructions. Fabricated But True Tom R. Halfhill is a BYTE senior editor based in San Mateo, California. You can reach him at thalfhill@bix.com. Letters / April 1996Pass the Results, PleaseIn "AMD K6 Takes On Intel P6" (January), I came upon the term register-result bypassing in a context unfamiliar to me. Usually, this term is used to describe the bypassing of the register file so that the results of instructions just executed are forwarded to the following instructions in parallel with the write-back stage. But what you describe happens "without accessing main memory." Do you refer to stores forwarding data to loads in the store buffer as "register-result bypassing," or is it some other feature? Gad S. Sheaffer IDC & PPD Architecture gss@iil.intel.com I meant to indicate that the K6 can bypass registers to provide results to subsequent instructions and that stores can forward data to loads. In other words, a load doesn't have to wait for a completed store instruction to put the result into memory; it can load the result directly from the store buffer. —Tom R. Halfhill, senior editor Copyright 1994-1998 BYTE |